- Ali's Newsletter
- Posts
- Unlocking the Power of RAG: Your Guide to Retrieval-Augmented Generation in 2025
Unlocking the Power of RAG: Your Guide to Retrieval-Augmented Generation in 2025
Advanced RAG Steps outlined here what are you waiting for 🚀 start scrolling
Ali Ali
July 24, 2025
Hey LinkedIn Fam! 👋In the rapidly evolving landscape of Artificial Intelligence, staying ahead means understanding the latest advancements that are truly reshaping how we interact with information. Today, we're diving deep into a groundbreaking technique that's making waves across industries: Retrieval-Augmented Generation (RAG). If you've ever wondered how AI can provide accurate, up-to-date, and contextually relevant answers without hallucinating, RAG is your answer.
Traditional Large Language Models (LLMs), while incredibly powerful, are inherently limited by the static nature of their training data. They can generate eloquent responses but often struggle with real-time information or domain-specific nuances, sometimes even fabricating information (hallucinations). RAG changes this paradigm entirely by bridging the gap between static knowledge and dynamic, real-time data retrieval. [1]
Let's explore how RAG works, its detailed steps, and how it compares to another crucial technique: fine-tuning.
What is Retrieval-Augmented Generation (RAG)?
RAG is a hybrid AI framework that integrates a retrieval mechanism with a generative model to improve the contextual relevance and factual accuracy of generated content. The retrieval mechanism fetches relevant external data from a knowledge base (e.g., vector databases, search engines, or local storage), while the generative model uses this retrieved information to produce coherent, contextually accurate text. [1]
This approach addresses several key challenges in large language models (LLMs):
•Limited Contextual Knowledge: LLMs are trained on fixed datasets and cannot update knowledge dynamically.
•Hallucination: Generative models often produce plausible-sounding but incorrect information.
•Scalability: RAG allows systems to access vast external databases, effectively bypassing memory constraints. [1]
How RAG Works: A Step-by-Step Process
RAG's architecture involves two primary components: a Retriever and a Generator. A common implementation of RAG typically follows these steps:
1.Query Encoding: The input query is transformed into a dense vector using a pre-trained embedding model (e.g., OpenAI's Ada, Sentence-BERT).
2.Document Retrieval: The query vector is matched against vectors in a pre-built document index (e.g., stored in a vector database like Pinecone, Weaviate, or Qdrant). Retrieval is typically performed using Approximate Nearest Neighbor (ANN) search for scalability and efficiency.
3.Contextual Fusion: The retriever returns the top-k documents, which are then appended to the original query as additional context. These documents may be processed (e.g., summarized, chunked) to ensure they fit within the input length limitations of the generator.
4.Response Generation: The generative model takes the enriched input (original query + retrieved documents) and generates a coherent and contextually relevant response. [1]
RAG vs. Fine-Tuning: Choosing the Right Approach
Both Retrieval-Augmented Generation (RAG) and fine-tuning are powerful techniques aimed at improving Large Language Models (LLMs). However, they achieve this through fundamentally different mechanisms and are suited for different use cases. Understanding their distinctions is crucial for making informed decisions in your AI strategy. [2]
Fine-tuning involves further training a pre-trained LLM on a smaller, more targeted dataset. This process adjusts the model's internal weights and parameters, embedding new knowledge directly into its architecture. Fine-tuning is ideal for tasks that require consistent performance within a specific domain, such as adapting an LLM to understand medical terminology or to generate text in a particular brand voice. [2]
RAG, on the other hand, enhances an LLM by retrieving information from external, up-to-date sources without modifying the underlying model. It acts as a dynamic knowledge layer, providing the LLM with real-time, relevant context to inform its responses. This makes RAG particularly effective for scenarios where information changes frequently or where access to a vast, external knowledge base is required. [2]
Here's a comparison to highlight their key differences:
Feature | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
Mechanism | Retrieves external information to augment the LLM's response. | Adjusts the LLM's internal parameters by training on a new dataset. |
Knowledge Source | External, dynamic knowledge bases (e.g., databases, documents, web). | Internal, static knowledge embedded during training. |
Data Updates | Easy to update; simply update the external knowledge base. | Requires retraining the model, which can be time-consuming and costly. |
Cost | Generally more cost-effective as it avoids extensive retraining. | Can be expensive due to computational resources and data labeling. |
Use Cases | Real-time information, domain-specific Q&A, reducing hallucinations. | Adapting to specific styles/tones, specialized terminology, consistent tasks. |
Transparency | High; can cite sources from retrieved documents. | Lower; knowledge is embedded, making source tracing difficult. |
Skill Set | Requires coding and architectural skills for pipeline setup. | Requires deep learning, NLP, and model configuration expertise. |
While fine-tuning bakes knowledge into the model, RAG provides a flexible and scalable way to keep LLMs informed with the latest information. Many advanced applications leverage both techniques for optimal performance. [2]
Advanced RAG Techniques: Pushing the Boundaries
As RAG continues to evolve, several advanced techniques have emerged to address its limitations and enhance its capabilities. These innovations aim to improve retrieval quality, context understanding, and overall accuracy. Some notable advanced RAG techniques include:
•Long RAG: Designed to handle lengthy documents more effectively by processing longer retrieval units (sections or entire documents) instead of small chunks. This preserves context and improves efficiency. [1]
•Self-RAG: Focuses on improving the generation process by allowing the LLM to decide when and what to retrieve, and to self-reflect on the quality of its generated responses. This iterative process enhances accuracy and reduces hallucinations.
•Corrective RAG (CRAG): Aims to correct retrieval errors by re-ranking retrieved documents or initiating new retrieval queries if the initial set is deemed irrelevant. This ensures that the generative model receives the most accurate context.
•Adaptive RAG: Dynamically adjusts the retrieval strategy based on the complexity of the query and the available knowledge sources. This allows for more flexible and efficient information retrieval.
•Graph RAG: Leverages knowledge graphs to enhance retrieval by understanding the relationships between entities and concepts. This provides a richer, more structured context for the generative model. [1]
These advanced techniques demonstrate the ongoing innovation in the RAG landscape, making it an even more robust and versatile solution for various AI applications.
Dive Deeper: Recommended Resources
To further your understanding of RAG and its applications, explore these valuable resources:
YouTube References (2025):
•RAG: The 2025 Best-Practice Stack by [Channel Name/Creator] - https://www.youtube.com/watch?v=vf9emNxXWdA [3]
•What is RAG? (Retrieval Augmented Generation = Smarter AI in 2025) by [Channel Name/Creator] - https://www.youtube.com/watch?v=GhzUzhBTo38 [3]
•Prompt Engineering Vs RAG Vs Finetuning Explained Easily by [Channel Name/Creator] - https://www.youtube.com/watch?v=6SO-8FcSkz4 [4]
•Fine-Tuning vs. RAG vs. AI Agents — Which Approach Fits Your Use Case? by [Channel Name/Creator] - https://www.youtube.com/watch?v=5zXuUjMJc34 [4]
Key Research Papers (2025):
•Deeper insights into retrieval augmented generation: The role of sufficient context (ICLR 2025) - https://research.google/blog/deeper-insights-into-retrieval-augmented-generation-the-role-of-sufficient-context/ [1]
•Retrieval Augmented Generation Evaluation in the Era of Large Language Models - https://arxiv.org/html/2504.14891v1 [1]
Visual Guide: Understanding RAG Architecture

Figure 1: Advanced RAG Architecture showing the complete pipeline from user query to response generation

Figure 2: Step-by-step RAG process flow illustrating how retrieval and generation work together
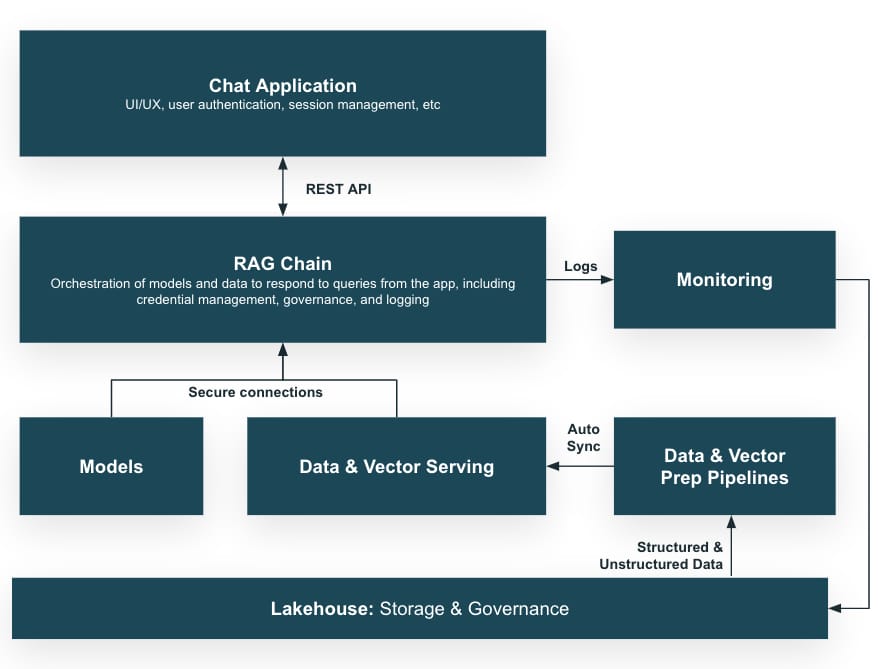
Figure 3: Visual comparison between RAG and Fine-tuning approaches
The Future of AI: Why RAG Matters
As we move deeper into 2025, RAG represents a fundamental shift in how we approach AI-powered applications. It's not just about having powerful language models; it's about making them truly intelligent by connecting them to the vast ocean of human knowledge. Whether you're building customer support chatbots, research assistants, or domain-specific AI applications, understanding and implementing RAG will be crucial for staying competitive.
The beauty of RAG lies in its flexibility and transparency. Unlike black-box solutions, RAG allows you to trace the source of information, update knowledge bases in real-time, and maintain control over what your AI knows. This transparency is becoming increasingly important as AI systems are deployed in critical applications across healthcare, finance, and education.
Ready to Implement RAG?
If you're excited about the possibilities of RAG and want to start implementing it in your projects, here are some next steps:
1.Start Small: Begin with a simple RAG implementation using existing tools like LangChain or LlamaIndex
2.Choose Your Vector Database: Explore options like Pinecone, Weaviate, or Qdrant based on your needs
3.Experiment with Embeddings: Test different embedding models to find what works best for your domain
4.Monitor and Iterate: Continuously evaluate your RAG system's performance and refine your approach
The AI revolution is here, and RAG is one of the most practical and powerful techniques you can master. Whether you're a developer, data scientist, or business leader, understanding RAG will give you a significant advantage in the AI-driven future.
Don't forget to follow for more AI insights and practical guides! 🚀
#AI #MachineLearning #RAG #RetrievalAugmentedGeneration #LLM #ArtificialIntelligence #TechInnovation #DataScience #NLP #2025Tech
References
[1] Eden AI. (2025). The 2025 Guide to Retrieval-Augmented Generation (RAG). Retrieved from https://www.edenai.co/post/the-2025-guide-to-retrieval-augmented-generation-rag
[2] Red Hat. (2024). RAG vs. fine-tuning. Retrieved from https://www.redhat.com/en/topics/ai/rag-vs-fine-tuning
[3] YouTube. (2025). RAG: The 2025 Best-Practice Stack. Retrieved from https://www.youtube.com/watch?v=vf9emNxXWdA
[4] YouTube. (2025). Prompt Engineering Vs RAG Vs Finetuning Explained Easily. Retrieved from