- Ali's Newsletter
- Posts
- 🚀 Supercharge Your LLM Inference: Mastering LMCache for Production 🧠
🚀 Supercharge Your LLM Inference: Mastering LMCache for Production 🧠
Hello LLM & ML Enthusiasts! 👋In the fast-paced world of Large Language Models (LLMs), we often find ourselves battling a common enemy: Inference Latency. Whether you're building a real-time RAG system or a complex multi-round agent, the "Time to First Token" (TTFT) can make or break the user experience. 📉Today, we're diving deep into LMCache, a game-changing KV-cache optimization layer that transforms LLM serving from compute-bound to cache-efficient. Let's explore how you can slash your TTFT by 3-10x and cut your GPU bills by up to 40%! 💸
Ali Ali
January 05, 2026
🔍 What is LMCache?
LMCache is an open-source (Apache 2.0) optimization layer designed to reuse Key-Value (KV) caches across different requests, instances, and even sessions. 🔄
Traditionally, LLMs recompute the KV cache for overlapping prompts (like in a chat history or shared RAG context), wasting precious GPU cycles. LMCache solves this by:
Hashing arbitrary segments of the prompt.
Storing the KV tensors in various backends (CPU, Disk, or Remote).
Retrieving and fusing them on subsequent hits, skipping the recomputation entirely! ⚡
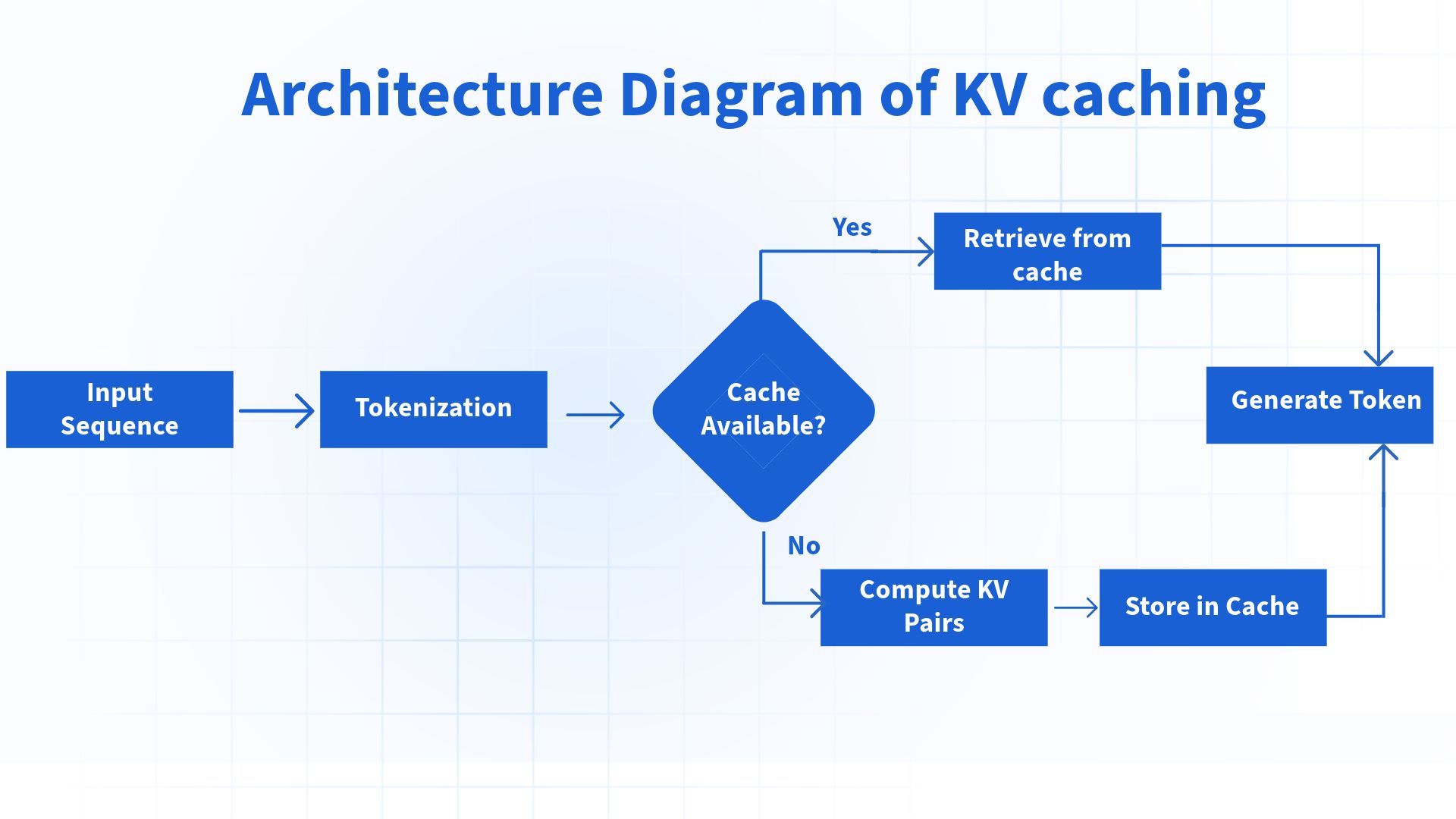
Figure 1: The standard flow of KV caching in LLM inference.
🏗️ The Architecture: How It Works Under the Hood
LMCache isn't just a simple cache; it's a sophisticated orchestration layer. Here are the core components:
Component | Role | How It Works |
|---|---|---|
Storage Manager | Orchestrator | Manages the lifecycle of backends (CPU, Disk, NIXL). Handles eviction via LRU logic. 🛠️ |
Cache Core | The Brain | Handles KV hashing (SHA) and lookup. Splits KV into chunks (e.g., 256 tokens) for granular reuse. 🧩 |
C++ Extensions | Performance | Uses CUDA/HIP kernels for high-speed tensor transfers between GPU and CPU/Disk. 🏎️ |
Connectors | Integration | Plugs directly into engines like vLLM and SGLang with minimal configuration. 🔌 |
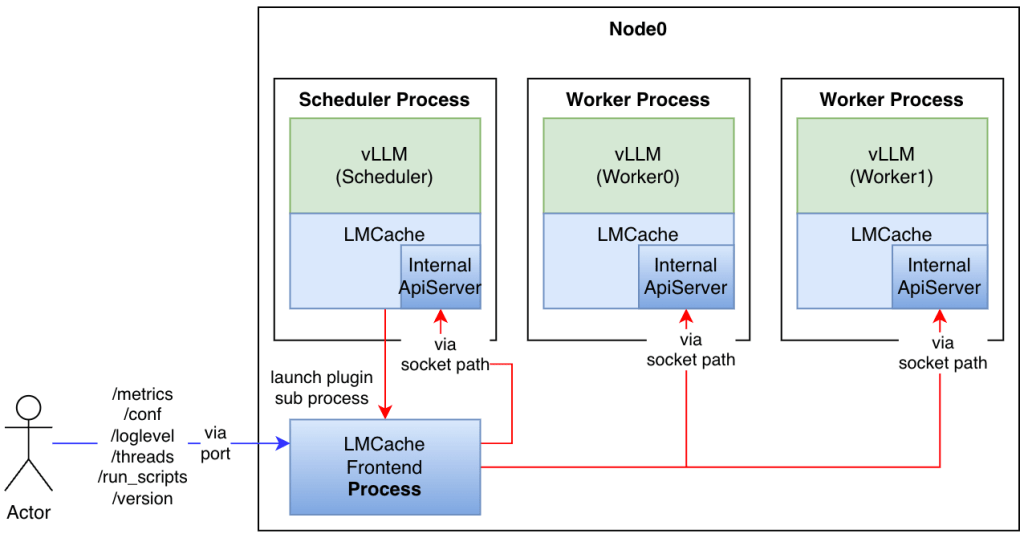
Figure 2: LMCache's internal architecture and integration with serving engines.
💡 Best Use Cases for LMCache
Where does LMCache shine the brightest? Here are the top production scenarios:
1. Retrieval-Augmented Generation (RAG) 📚
In RAG, users often query the same set of documents. By caching the KV tensors of these documents, you can achieve a 5x+ speedup in TTFT.
Pro Tip: Pair LMCache with your vector database to pre-warm caches for the most frequently retrieved documents!
2. Multi-Round Conversational Agents 💬
Stop recomputing the entire chat history every time the user sends a new message. LMCache stores the history's KV cache, making long conversations feel instantaneous.
3. Distributed LLM Serving 🌐
Using NIXL (Remote Backend), you can share caches across a cluster of GPUs. This is perfect for enterprise-scale deployments where multiple instances serve the same model.

Figure 3: Comparing traditional RAG with Cache-Augmented Generation (CAG).
🛠️ Hands-on: Implementing LMCache with vLLM
Ready to get your hands dirty? Here’s how you can integrate LMCache into your vLLM stack today! 💻
Step 1: Installation
Ensure you have an NVIDIA GPU (CC ≥ 7.0) and Linux environment.
pip install lmcache vllm==0.4.2 # Ensure version compatibility!
Step 2: Python Integration
from vllm import LLM
# Initialize LLM with LMCache backend
model = LLM(
model="meta-llama/Llama-2-7b-hf",
kv_offloading_backend="lmcache",
kv_offloading_size=10, # 10GB cache size
disable_hybrid_kv_cache_manager=True
)
# The first run computes and stores the cache
outputs = model.generate("Your long system prompt or document context...")
# Subsequent runs with overlapping prompts will be LIGHTNING fast! ⚡
⚠️ Common Pitfalls & How to Avoid Them
Even the best tools have their quirks. Here’s what I’ve learned from the trenches:
Hardware Lock-in: LMCache is primarily Linux/NVIDIA-centric. While ROCm (AMD) is supported, it can be finicky. 🐧
I/O Overhead: Disk backends are great for persistence but have higher latency. Use CPU RAM for "hot" caches to keep things snappy. 🧠
Version Mismatches: Torch and vLLM versions are critical. Always pin your versions (e.g., Torch 2.4.0) to avoid cryptic crashes. 📌
Chunk Size: Using a small
chunk_size(like 8) leads to storage fragmentation. Stick to 256+ for production workloads. 📏
📈 The Verdict
LMCache is a must-have for any serious ML engineer looking to optimize production LLM deployments. It bridges the gap between raw compute power and intelligent resource management. 🌉
Action Plan:
Start local with a CPU backend.
Monitor your Cache Hit Rate using Prometheus.
Scale to distributed NIXL for cluster-wide efficiency.
Happy Caching! 🚀
If you enjoyed this deep dive, feel free to share it with your fellow ML engineers! For more details, check out the official LMCache repo. 🌟